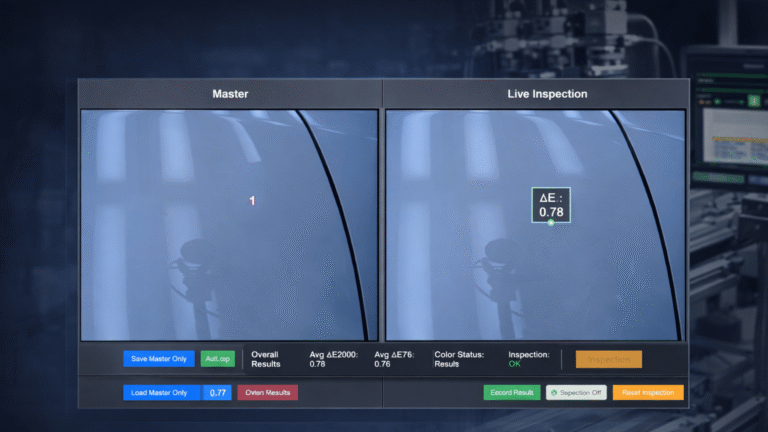
Building a computer vision model is just the beginning. The real challenge lies in ensuring that it performs consistently in complex, ever-changing production environments.
From harsh lighting and occlusions to unpredictable product variations, every real-world scenario poses unique challenges. That’s exactly where Hypervise—Eternal Robotics’ AI-powered industrial vision platform—proves its value.
At Hypervise, we go beyond building models—we stress-test them across production scenarios to ensure consistent, high-precision results at scale.
How We Test Hypervise Models for Real-World Readiness
Hypervise follows a rigorous model validation pipeline that evaluates performance across four key dimensions:
- Accuracy – Does the model detect and classify defects with high precision and recall?
- Speed – Can it keep pace with production line speeds or real-time system latencies?
- Robustness – Can it handle edge cases like low lighting, occlusion, or contrast issues?
- Generalization – Can it maintain performance across different batches, shifts, and environments?
The Metrics That Matter at Hypervise
We don’t just test models—we measure what counts:
- Precision, Recall, F1 Score – Crucial for understanding defect classification accuracy.
- IoU (Intersection over Union) – The gold standard for bounding box accuracy in object detection.
- mAP (Mean Average Precision) – A robust metric to evaluate object detection across classes and confidence thresholds.
Smart Dataset Structuring to Avoid Inflated Scores
Hypervise ensures rigorous dataset handling to avoid overfitting or inflated results:
- Training (60–70%): Where the model learns.
- Validation (15–20%): For hyperparameter tuning and early stopping.
- Testing (15–20%): Used strictly for final model evaluation.
We also take special care to prevent data leakage—by isolating production batches or camera sources—to evaluate true generalization.
Handling Edge Cases—Not Just in Theory
In real-world manufacturing, edge cases aren’t occasional—they’re frequent. Hypervise prepares for them with:
| Problem | Hypervise Solution |
|---|---|
| Low light or contrast | Histogram equalization + lighting-varied training |
| Occlusion | Training with partially visible objects |
| Angles & orientation | Augmentation with rotation & perspective shift |
| Background clutter | Attention layers and masking techniques |
| Scale variance | Multi-scale training and diverse data coverage |
| Blurred images | Balanced training using high & low-res inputs |
Testing for Production, Not Just Accuracy
Hypervise integrates real-world performance validation into its core development process:
- Data Augmentation: Simulating lighting, blur, zoom, and background changes during training.
- Regularization: Dropout and L2 penalties to prevent overfitting.
- Ensemble Learning: Using multiple models to improve overall robustness and reduce false positives.
- Cross-Validation: Evaluating across multiple dataset splits for more reliable performance estimates.
CI/CD for Vision AI: Automating Trust
With Hypervise, we integrate Continuous Integration and Deployment (CI/CD) into our vision pipeline:
- CI (Continuous Integration): Version-controlled model training and validation.
- CD (Continuous Deployment): Controlled releases that meet predefined performance thresholds.
- CT (Continuous Testing): Real-time checks against regression, drift, and low-confidence predictions.
Example: A new model build is only deployed if it beats F1 > 0.9 and maintains low false positives in edge cases.
Still Struggling With Unreliable Vision AI?
With Hypervise, you don’t just get a model—you get a production-tested AI inspection platform built specifically for industrial needs. It’s already delivering results in semiconductor lines, automotive inspection stations, and electronics assembly units.
FAQs – Hypervise’s Take
Hypervise typically targets F1 > 0.9 and IoU > 0.5 as thresholds, but more importantly, looks at performance consistency across production conditions and shifts.
We recommend hundreds of diverse, real-world examples per defect class—focusing on coverage, not just quantity.
Partially. Hypervise includes unsupervised monitoring and anomaly detection for post-deployment inference validation, but for robust classification metrics, labeled data remains key.
Hypervise tracks prediction confidence, defect frequency shifts, and human review feedback to flag drift and trigger automated retraining cycles.
Conclusion: Don’t Just Build. Validate.
At Hypervise, testing is a first-class citizen—not an afterthought.
From data pipelines and metric thresholds to edge case training and CI/CD integration, Hypervise is built to perform where it matters most: on your factory floor, in real time, under pressure.
Ready to deploy industrial vision AI that actually works in production? Request a demo to see Hypervise in action.